혼자 공부하는 머신러닝+딥러닝 Chapter 5 발표
5. 트리 알고리즘
5-1. 결정 트리
- 결정 트리(Decision Tree):
예 / 아니오에 대한 질문을 이어나가면서 정답을 찾아 학습하는 알고리즘 - 노드(node):
결정 트리를 구성하는 핵심 요소 - 루트 노드(root node):
결정 트리 맨 위의 노드 - 리프 노드(leaf node):
결정 트리 맨 아래 노드 - 부모 노드(parent node):
어떤 하나의 노드에 대하여 이 노드의 상위에 연결된 노드 - 자식 노드(child node):
어떤 하나의 노드에 대하여 이 노드의 하위에 연결된 노드판다스 데이터프레임의 유용한 메서드 2개
- info() 메서드:
데이터 프레임의 각 열의 데이터 타입과 누락한 데이터가 있는지 확인하는데 유용\ - describe() 메서드:
평균(mean), 표준편차(std), 최소(min), 최대(max), 중간값 (50%), 1분위사수(25%), 3분위사수(75%) 제공
- info() 메서드:
로지스틱 회귀로 와인 분류하기
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 와인 데이터 준비
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine-date')
# 넘파이 배열로 바꾸고 훈련 세트와 테스트 세트로 나누기
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
# StandardScaler 클래스를 사용하여 훈련 세트 전처리
from sklearn.preprocessing import StandardScaler
ss = StandardScaler()
ss.fit(train_input)
train_scaled = ss.transform(train_input)
test_scaled = ss.transform(test_input)
# 표준점수로 변환된 train_scaled와 test_scaled를 사용해 로지스틱 회귀 모델을 훈련
from sklearn.linear_model import LogisticRegression
lr = LogisticRegression()
lr.fit(train_scaled, train_target)
print(lr.score(train_scaled, train_target))
print(lr.score(test_scaled, test_target))
0.7808350971714451 0.7776923076923077
훈련 세트와 테스트 세트의 점수가 모두 낮으므로 모델이 다소 과소적합
결정 트리
결정 트리는 다음 그림과 같이 스무고개와 같다.
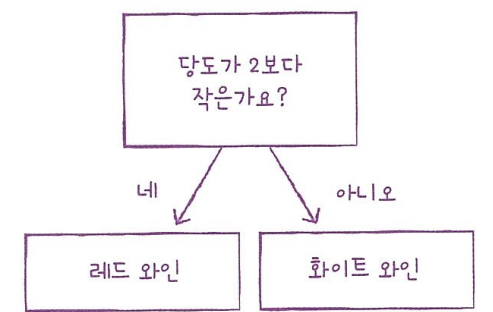
사이킷런의 DecisionTreeClassifier 클래스를 사용해 결정 트리 모델 훈련해보기
1
2
3
4
5
6
# 결정 트리 모델 훈련
from sklearn.tree import DecisionTreeClassifier
dt = DecisionTreeClassifier()
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
0.996921300750433 0.8576923076923076
훈련 세트에 대한 점수가 엄청 높고 테스트 세트의 성능은 그에 비해 조금 낮으므로 과대적합된 모델 plot_tree() 함수를 사용해 이해하기 쉬운 트리 그림으로 출력하기
1
2
3
4
5
6
# 트리 그림 출력
import matplotlib.pyplot as plt
from sklearn.tree import plot_tree
plt.figure(figsize=(10, 7))
plot_tree(dt)
plt.show()
너무 복잡하므로 보기 간단하게 만들기
1
2
3
4
5
6
7
plt.figure(figsize=(10, 7))
# 트리 깊이 제한(max_depth 매개변수)
# 노드 색 칠하기(filled 매개변수)
# 노드 이름 전달(feature_names 매개변수)
plot_tree(dt, max_depth=1, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
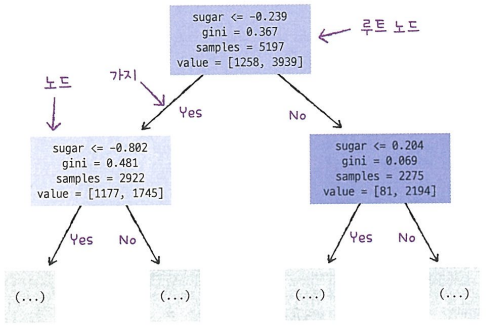 \
\
노드
노드는 다음과 같은 정보를 담고 있다.
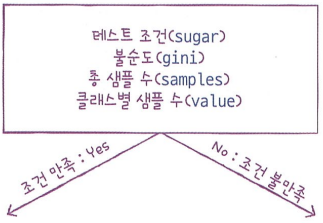 \
\
여기서 gini란?
- DecisionTreeClassifier 클래스에서 노드의 데이터 분할 기준을 정하는 criterion 매개변수의 기본값
- 지니 불순도(Gini impurity)를 의미
- 지니 불순도 계산법 :
1 - (음성 클래스 비율2 + 양성 클래스 비율2)- 정보 이득 : 부모와 자식 노드 사이의 불순도의 차이
- 정보 이득 계산법 :
부모의 불순도-(왼쪽 노드 샘플 수/부모의 샘플 수)x왼쪽 노드 불순도-(오른쪽 노드 샘플 수/부모의 샘플 수)x오른쪽 노드 불순도- 엔트로피 불순도 : 사이킷런에는 criterion=’entropy’로 지정하여 사용하는 또 다른 불순도 기준
- 엔트로피 불순도 계산법 :
-음성 클래스 비율 x log2(음성 클래스 비율) - 양성 클래스 비율x log2(양성 클래스 비율)
가지치기
무작정 끝까지 자라나는 트리가 만들어지는 것을 방지하기 위해 트리의 최대 깊이를 지정
1
2
3
4
dt = DecisionTreeClassifier(max_depth=3, random_state=42)
dt.fit(train_scaled, train_target)
print(dt.score(train_scaled, train_target))
print(dt.score(test_scaled, test_target))
0.8454877814123533 0.8415384615384616
훈련 세트의 성능은 낮아졌지만 테스트 세트의 성능은 거의 그대로
1
2
3
4
# 트리 그래프 그리기
plt.figure(0, figsize=(20, 15))
plot_tree(dt, filled=True, feature_names=['alcohol', 'sugar', 'pH'])
plt.show()
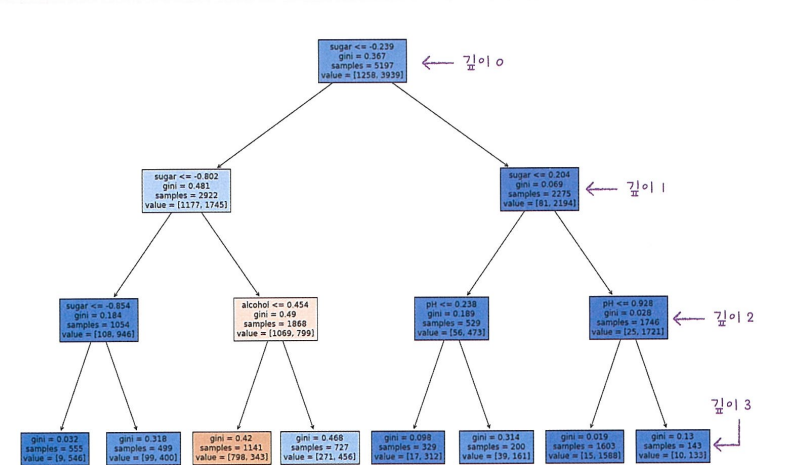
결정 트리는 어떤 특성이 가장 유용한지 나타내는 특성 중요도를 계산해줌.
위 트리의 루트 노드와 깊이 1에서 당도를 사용했기 때문에 당도가 가장 유용한 특성 중 하나일 것으로 추측됨.
- 특성 중요도 :
결정 트리에 사용된 특성이 불순도를 감소하는데 기여한 정도 - 특성 중요도 계산법 :
각 노드의 정보 이득과 전체 샘플에 대한 비율을 곱한 후 특성별로 더하여 계산
5-2. 교차 검증과 그리드 서치
검증 세트(validation set)
테스트 세트를 사용하지 않으면 모델의 과대적합/과소적합 여부를 판단하기 어려움
이 때, 훈련 세트를 또 나눈 데이터인 검증 세트를 사용
- 검증 세트 사용법
- 훈련 세트로 모델을 훈련, 검증 세트로 모델을 평가
- 훈련 세트와 검증세트를 합쳐 모델을 훈련, 테스트 세트로 모델을 평가
 \
\
교차 검증(cross validation)
많은 데이터를 훈련에 사용할 수록 좋은 모델이 만들어지지만 검증 세트를 만들 때 훈련 세트가 줄어듦
이 때, 교차 검증을 이용하면 안정적인 검증 점수를 얻고 더 많은 데이터 사용 가능
- 3-폴드 교차 검증 : 훈련 세트를 세 부분으로 나눠서 교차 검증을 수행하는 것
- 보통 5-폴드 교차 검증이나 10-폴드 교차 검증을 많이 사용(데이터의 80~90%까지 훈련에 사용할 수 있기 때문)
3-폴드 교차 검증 그림 {: .prompt-info }
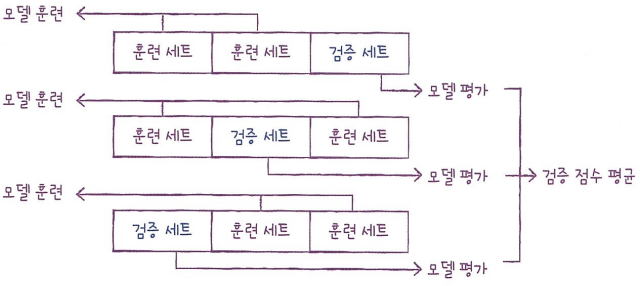
cross_validate() : 교차 검증 함수
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 와인 데이터 불러오기
import pandas as pd
wine = pd.read_csv('https://bit.ly/wine-date')
#class 열 타깃 사용, 나머지 열은 특성 배열에 저장
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
#훈련 세트와 테스트 세트 나누기
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
#교차 검증 함수 사용
from sklearn.model_selection import cross_validate
scores = cross_validate(dt, train_input, train_target)
print(scores)
{'fit_time': array([0.01305008, 0.01255631, 0.00827003, 0.00501585, 0.00501204]), 'score_time': array([0.00238919, 0.00131226, 0.00170016, 0.00133657, 0.00118709]), 'test_score': array([0.84230769, 0.83365385, 0.84504331, 0.8373436 , 0.8479307 ])}
- 이 함수는 fit_time, score_time, test_score 키를 가진 딕셔너리를 반환함
- 처음 2개의 키는 모델을 훈련하는 시간과 검증하는 시간 의미
- 각 키마다 5개의 숫자가 담겨있는데 cross_validate() 함수가 기본적으로 5-폴드 교차 검증을 수행하기 때문
1 2
import numpy as np print(np.mean(scores['test_score']))
0.8412558303102096
하이퍼파라미터 튜닝
- 모델 파라미터 : 머신러닝 모델이 학습하는 파라미터
- 하이퍼파라미터 : 모델이 학습할 수 없어 사용자가 지정해야만 하는 파라미터
- 하이퍼파라미터 튜닝 작업 :
- 라이브러리가 제공하는 기본값을 그대로 사용해 모델 훈련
- 검증 세트의 점수나 교차 검증을 통해서 매개변수를 조금씩 바꿔 봄
- max_depth 매개변수와 min_samples_split 매개변수를 동시에 바꿔가며 최적의 값을 찾아야함
- 사이킷런에서 제공하는 그리드 서치를 사용
그리드서치 사용 과정
- 탐색할 매개변수 지정
- 훈련 세트에서 그리드 서치를 수행하여 최상의 평균 검증 점수가 나오는 매개변수 조합 찾기
- 그리드 서치는 최상의 매개변수에서 전체 훈련 세트를 사용해 최종 모델을 훈련
- 그리드 서치 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
from sklearn.model_selection import GridSearchCV
# 파라미터 딕셔너리
params = {'min_impurity_decrease': np.arange(0.0001, 0.001, 0.0001),
'max_depth': range(5, 20, 1),
'min_samples_split': range(2, 100, 10)
}
# 그리드 서치 진행 및 학습
gs = GridSearchCV(DecisionTreeClassifier(random_state=42), params, n_jobs=-1)
gs.fit(train_input, train_target)
# 최적의 모델을 통해 평가
dt = gs.best_estimator_
print(dt.score(train_input, train_target))
# 최적의 모델 파라미터
print(gs.best_params_)
>>> {'max_depth': 14, 'min_impurity_decrease': 0.0004, 'min_samples_split': 12}
# 교차 검증의 최대 점수
print(np.max(gs.cv_results_['mean_test_score']))
>>> 0.8683
랜덤 서치
- 매개변수 값의 목록을 전달하는 것이 아니라 매개변수를 샘플링할 수 있는 확률 분포 객체를 전달
- 연속된 매개변수 값을 탐색할 때 유용
-랜덤 서치 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 랜덤 서치
from scipy.stats import uniform, randint
# 파라미터 딕셔너리
params = {'min_impurity_decrease': uniform(0.0001, 0.001),
'max_depth': randint(20, 50),
'min_samples_split': randint(2, 25),
'min_samples_leaf': randint(1, 25),
}
# 랜덤 서치 진행 및 학습
from sklearn.model_selection import RandomizedSearchCV
gs = RandomizedSearchCV(DecisionTreeClassifier(random_state=42), params,
n_iter=100, n_jobs=-1, random_state=42)
gs.fit(train_input, train_target)
# 최적의 모델 파라미터
print(gs.best_params_)
>>> {'max_depth': 39, 'min_impurity_decrease': 0.00034102546602601173, 'min_samples_leaf': 7, 'min_samples_split': 13}
# 교차 검증의 최대 점수
print(np.max(gs.cv_results_['mean_test_score']))
>>> 0.8695
# 최적의 모델을 통해 평가
dt = gs.best_estimator_
print(dt.score(test_input, test_target))
>>> 0.86
5-3. 트리의 앙상블
- 정형 데이터(structured data) : 어떤 구조로 되어 있는 데이터
- 예시 : CSV, 데이터베이스,Excel에 저장하기 쉬운 프로그래머가 다루는 대부분의 데이터
- 비정형 데이터(unstructured data) : 정형 데이터와 반대되는 데이터
- 예시 : 데이터베이스나 엑셀로 표현하기 어려운 텍스트 데이터, 디지털카메라로 찍은 사진, 디지털 음악 등
앙상블 학습(ensemble learning)
- 더 좋은 예측 결과를 만들기 위해 여러 개의 모델을 훈련하는 머신러닝 알고리즘
- 대부분 결정 트리를 기반으로 만들어져 있음
랜덤 포레스트(Random Forest)
- 대표적인 결정 트리 기반의 앙상블 학습 방법
- 결정 트리를 랜덤하게 만들어 결정 트리(나무)의 숲을 만듦
- 각 결정 트리의 예측을 사용해 최종 예측을 만듦
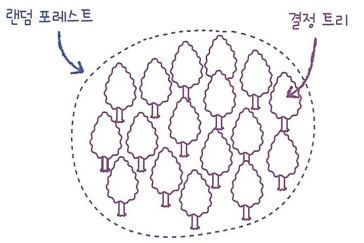
- 부트스트랩 샘플 : 데이터 샘플로부터 반복적으로 무작위 표본 추출을 수행하는 방법
데이터 세트에서 중복을 허용하여 샘플링하며, 기본적으로 훈련 세트의 크기와 같게 만듦
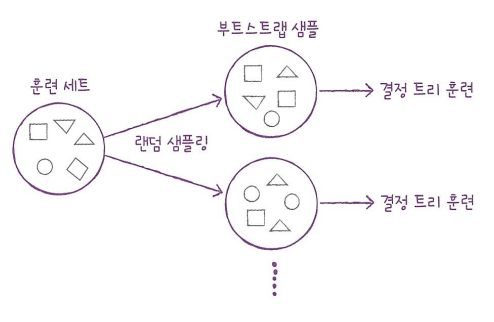
- RandomForestClassifier : 분류 모델로, 기본적으로 전체 특성 개수의 제곱근만큼의 특성을 선택
- RandomForestRegressor : 랜덤 포레스트 회귀 모델
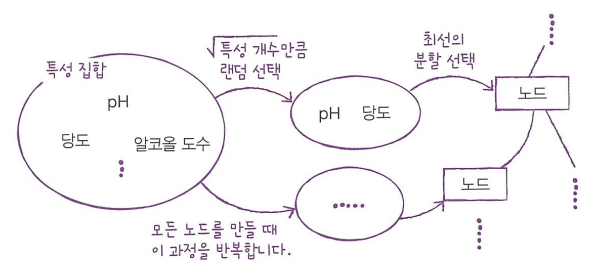
- 랜덤 포레스트 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 데이터 준비
import numpy as np
import pandas as pd
from sklearn.model_selection import train_test_split
wine = pd.read_csv('https://bit.ly/wine_csv_data')
data = wine[['alcohol', 'sugar', 'pH']].to_numpy()
target = wine['class'].to_numpy()
# 데이터 나누기
train_input, test_input, train_target, test_target = train_test_split(data, target, test_size=0.2, random_state=42)
# 랜덤 포레스트 모델링 및 교차검증
from sklearn.model_selection import cross_validate
from sklearn.ensemble import RandomForestClassifier
rf = RandomForestClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(rf, train_input, train_target, return_train_score=True, n_jobs=-1)
# 교차 검증 점수
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
>>> 0.9973 0.8905
# 특성 중요도 계산
rf.fit(train_input, train_target)
print(rf.feature_importances_)
>>> [0.23167441 0.50039841 0.26792718]
# oob sample을 통한 평가
rf = RandomForestClassifier(oob_score=True, n_jobs=-1, random_state=42)
rf.fit(train_input, train_target)
print(rf.oob_score_)
>>> 0.8934
- 랜덤 포레스트는 자체적으로 모델을 평가하는 점수를 얻을 수 있음
엑스트라 트리
- 랜덤 포레스트와 비슷하게 동작하는 결정 트리 기반의 앙상블 학습 방법
- 부트스트랩 샘플을 사용하지 않음
- 노드를 분할할 때 가장 좋은 분할을 찾는 것이 아닌 무작위로 분할
- 랜덤하게 노드를 분할하기 때문에 빠른 계산 속도가 장점
- ExtraTreesClassifier : 엑스트라 트리 분류 모델
- ExtraTreesRegressor : 엑스트라 트리 회귀 모델
- 엑스트라 트리 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 엑스트라 트리 모델링
from sklearn.ensemble import ExtraTreesClassifier
et = ExtraTreesClassifier(n_jobs=-1, random_state=42)
scores = cross_validate(et, train_input, train_target, return_train_score=True, n_jobs=-1)
# 교차검증 점수
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
>>> 0.9974503966084433 0.8887848893166506
# 특성 중요도 계산
et.fit(train_input, train_target)
print(et.feature_importances_)
>>> [0.20183568 0.52242907 0.27573525]
그레이디언트 부스팅
- 랜덤 포레스트나 엑스트라 트리와 달리 결정 트리를 연속적으로 추가하여 손실 함수를 최소화하는 앙상블 방법
- 훈련 속도가 조금 느리지만 더 좋은 성능 기대할 수 있음
- GradientBoostingClassifier : 그레이디언트 부스팅 분류 모델
- GradientBoostingRegressor : 그레이디언트 부스팅 회귀 모델
- 그레이디언트 부스팅 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# 그레이디언트 부스팅 모델링 및 교차 검증
from sklearn.ensemble import GradientBoostingClassifier
gb = GradientBoostingClassifier(n_estimators=500, learning_rate=0.2, random_state=42)
scores = cross_validate(gb, train_input, train_target, return_train_score=True, n_jobs=-1)
# 교차 검증 점수
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
>>> 0.9464595437171814 0.8780082549788999
# 특성 중요도 계산
gb.fit(train_input, train_target)
print(gb.feature_importances_)
>>> [0.15872278 0.68010884 0.16116839]
히스토그램 기반 그레이디언트 부스팅
- 그레이디언트 부스팅의 속도를 개선한 것이며, 안정적인 결과와 높은 성능으로 인기가 높음
- HistGradientBoostingClassifier : 히스토그램 기반 그레이디언트 부스팅 분류 클래스
- 히스토그램 기반 그레이디언트 부스팅 코드
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
# 히스토그램 기반 그레이디언트 부스팅 모델링 및 교차검증
from sklearn.ensemble import HistGradientBoostingClassifier
hgb = HistGradientBoostingClassifier(random_state=42)
scores = cross_validate(hgb, train_input, train_target, return_train_score=True, n_jobs=-1)
# 교차검증 점수
print(np.mean(scores['train_score']), np.mean(scores['test_score']))
>>> 0.9321723946453317 0.8801241948619236
# 특성 중요도 계산
hgb.fit(train_input, train_target)
result = permutation_importance(hgb, train_input, train_target, n_repeats=10,
random_state=42, n_jobs=-1)
print(result.importances_mean)
>>> [0.08876275 0.23438522 0.08027708]
result = permutation_importance(hgb, test_input, test_target, n_repeats=10,
random_state=42, n_jobs=-1)
print(result.importances_mean)
>>> [0.05969231 0.20238462 0.049]