혼자 공부하는 머신러닝+딥러닝 Chapter 3
3. 회귀 알고리즘과 모델 규제
3-1. k-최근접 이웃 회귀
k-최근접 이웃 회귀
지도 학습 알고리즘의 종류 두가지
- 분류 : 샘플을 몇 개의 클래스 중 하나로 분류하는 문제
- 회귀 : 임의의 어떤 숫자를 예측하는 문제\
k-최근접 이웃 분류 알고리즘 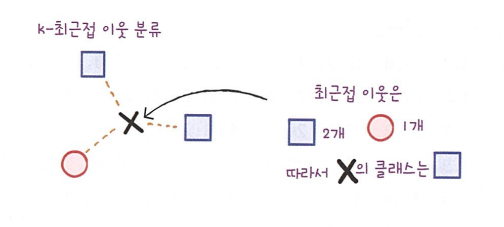 k-최근접 이웃 회귀 알고리즘
k-최근접 이웃 회귀 알고리즘 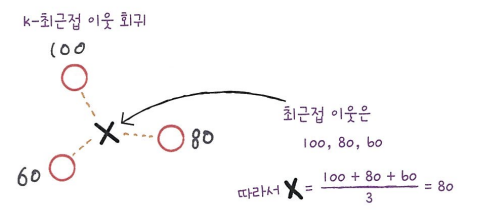
데이터 준비
1
2
3
4
5
6
7
8
9
10
11
12
13
14
import numpy as np
perch_length = np.array([8.4, 13.7, 15.0, 16.2, 17.4, 18.0, 18.7, 19.0, 19.6, 20.0, 21.0,
21.0, 21.0, 21.3, 22.0, 22.0, 22.0, 22.0, 22.0, 22.5, 22.5, 22.7,
23.0, 23.5, 24.0, 24.0, 24.6, 25.0, 25.6, 26.5, 27.3, 27.5, 27.5,
27.5, 28.0, 28.7, 30.0, 32.8, 34.5, 35.0, 36.5, 36.0, 37.0, 37.0,
39.0, 39.0, 39.0, 40.0, 40.0, 40.0, 40.0, 42.0, 43.0, 43.0, 43.5,
44.0])
perch_weight = np.array([5.9, 32.0, 40.0, 51.5, 70.0, 100.0, 78.0, 80.0, 85.0, 85.0, 110.0,
115.0, 125.0, 130.0, 120.0, 120.0, 130.0, 135.0, 110.0, 130.0,
150.0, 145.0, 150.0, 170.0, 225.0, 145.0, 188.0, 180.0, 197.0,
218.0, 300.0, 260.0, 265.0, 250.0, 250.0, 300.0, 320.0, 514.0,
556.0, 840.0, 685.0, 700.0, 700.0, 690.0, 900.0, 650.0, 820.0,
850.0, 900.0, 1015.0, 820.0, 1100.0, 1000.0, 1100.0, 1000.0,
1000.0])
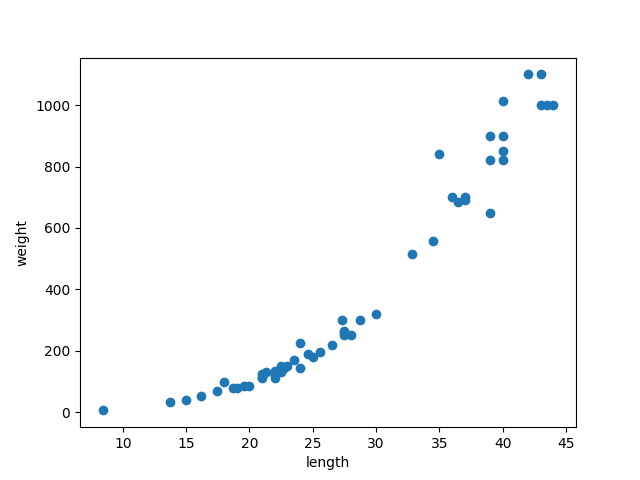
위의 농어의 데이터를 바탕으로 산점도를 그려 형태를 파악해봅시다.
1
2
3
4
5
import matplotlib.pyplot as plt
plt.scatter(perch_length, perch_weight)
plt.xlabel('length')
plt.ylabel('weight')
plt.show()
 \
\
농어의 길이가 커짐에 따라 무게도 늘어나네요.
이제 농어 데이터를 머신러닝 모델에 사용하기 전에 훈련 세트와 테스트 세트로 나눠봅시다.
1
2
from sklearn.model_selection import train_test_split
train_input, test_input, train_target, test_target = train_test_split(perch_length, perch_weight, random_state=42)
numpy의 reshape() 메서드를 사용하여 배열의 크기를 변경합니다.
1
2
3
train_input = train_input.reshape(-1,1)
test_input = test_input.reshape(-1,1)
print(train_input.shape, test_input.shape)
(42, 1) (14, 1) 이제 준비한 훈련 세트를 활용하여 k-최근접 이웃 알고리즘을 훈련시켜 보죠.
결정계수(R2)
사이킷런에서 k-최근접 이웃 회귀 알고리즘을 구현한 클래스는 KNeighborsRegressor입니다.
이 클래스의 사용법은 KNeighborsClassifier와 매우 비슷합니다.
객체를 생성하고 fit() 메서드로 회귀 모델을 훈련하겠습니다.
1
2
3
4
5
6
from sklearn.neighbors import KNeighborsRegressor
knr = KNeighborsRegressor()
# k-최근접 이웃 회귀 모델을 훈련합니다
knr.fit(train_input, train_target)
이제 테스트 세트의 점수를 확인해 보죠.
1
print(knr.score(test_input, test_target))
0.992809406101064
이 점수를 결정계수 또는 간단히 R2라고 부릅니다. 결정계수의 계산 방식은 다음과 같습니다. R^2^ = 1 - (타깃 - 예측)2/(타깃 - 평균)2
This post is licensed under CC BY 4.0 by the author.